The end of the "one-size-fits-all" chatbot: A guide to your five new AI brains



Many AI chatbots offer a choice of models, but these are usually variations created by the same provider. They may differ in speed, reasoning style, or focus, but they’re generally built on the same underlying data and architecture, which means their strengths and limitations are often similar.
ExpressAI brings together five AI models from different providers, each specialized for a particular strength. This guide will show you how each model works and when to use it, so you can get the most accurate and relevant answers for every prompt.
What is an AI model?
When you type a question into an AI chatbot, two things are involved: the interface and the model. The interface is what you see and interact with: the text box, the buttons, and the conversation window. The AI model is the system behind it that reads your input, processes it, and generates a response.
Why one AI model isn’t enough
No single AI model is equally strong at every type of task. For example, a model that’s trained to write fluently may not reason well over numbers or be able to process images.
When you rely on a single model, you’re bound by its limitations. If you give the same AI model a quick creative writing task and then a complex mathematical problem, the model applies the same approach regardless of what the task actually needs. Both inputs will produce a response, but the response could be a poor fit for at least one of them.
Why different models give different answers
Different models provide different results to the same input because they’re usually trained on different data, with different objectives, and with different architectural choices made by their developers.
Training data
Training data is the material a model learns from, such as books, web pages, code repositories, research papers, or images. The type, quality, and volume of that data directly shape how it responds.
For example, a model trained heavily on code has been exposed to more programming patterns and syntax, so it usually performs better on coding tasks. One trained across many languages has seen more multilingual examples, which can improve responses in those languages. A model trained mostly on general web text may be better at conversational writing but less precise on technical tasks.
Training method
The training method is how the model learns to use the training data. Two models can be trained on identical data and still behave very differently depending on how they were trained.
Some models learn from large sets of example prompts paired with answers, teaching them to follow instructions and respond in a particular way. So a model trained on formal, precise examples will tend to produce structured, measured responses, while one trained on more conversational examples will feel looser and more natural.
Others go through an additional post-training stage where model responses are ranked or scored, usually by human reviewers, and the model is further tuned to improve reasoning, accuracy, or instruction following. In this case, because different teams apply different criteria, like prioritizing safety, helpfulness, or creativity, two models put through this process will develop different tendencies, even if they started from similar foundations.
Some smaller models are distilled from larger ones. The large model first generates high-quality answers, and the smaller model is trained to mimic them in a more compact system. Because this is an approximation rather than a perfect replication, the smaller model may respond differently on complex or ambiguous inputs.
Architecture
A model’s architecture is its internal design. It determines how the model is structured, how information flows through it, and how much capacity it has to process and represent complex patterns.
Some of the most common architectural approaches used in modern AI models are:
- Transformer: A transformer architecture compares every part of the input with every other part, which helps it understand relationships across a full paragraph or document. Because it looks at everything at once, it’s very good at picking up on connections between distant parts of a text, but it becomes more computationally expensive as inputs get longer.
- Mixture-of-experts (MoE): An MoE is a design pattern used within transformer-based models that splits the model into many specialized parts, called "experts." For each prompt, only a small number of experts activate. This means the model can be huge overall but only uses a fraction of itself at any given time. Two similar prompts might route to different experts and get noticeably different responses as a result.
- Mamba: This reads the input in order, from beginning to end. As it moves forward, it keeps a running summary of what it has already read and uses that to interpret what comes next. Since it doesn’t compare the entire input at once, it handles long text more efficiently and works well for tasks where each step builds on the previous one.
Models can combine these designs. A hybrid model may use Mamba layers for efficiency, with transformer layers added where the model needs to connect details across long passages.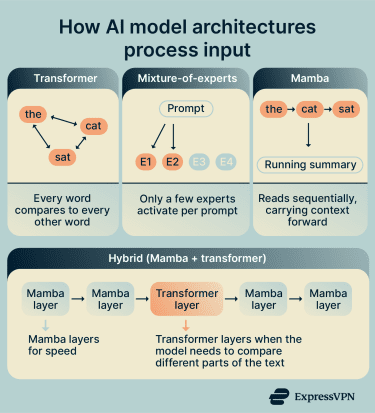
Beyond architecture, two other structural properties affect how a model responds. The first is size, measured in parameters, which are the numerical values the model adjusts during training to learn patterns. The more parameters a model has, the more capacity it has to represent complex ideas. A smaller model may respond confidently but miss nuance that a larger one would catch.
The second is the context window, or how much text the model can consider at once. A model with a small context window may lose track of earlier parts of a conversation, while one with a larger window can hold more in view and produce more consistent responses.
The five models in ExpressAI
ExpressAI includes five models: one each from OpenAI, DeepSeek, and NVIDIA, and two from Alibaba (Qwen). Every model is open weight and designed for a different type of task.
GPT OSS 120B: General-purpose model
GPT OSS 120B is built by OpenAI. It uses a mixture-of-experts (MoE) design pattern with 117 billion total parameters, but only about 5 billion are active for any given prompt. The model routes each input to the most relevant experts rather than running everything at once. Because only a small portion of the model runs per prompt, responses stay fast even though the model has many more parameters in total.
DeepSeek R1 Distill 32B: Reasoning-focused model
DeepSeek R1 Distill 32B is a reasoning-focused model built on Alibaba's Qwen2.5 architecture and fine-tuned by DeepSeek. Rather than training it from scratch, DeepSeek used its larger R1 model, trained to produce detailed, step-by-step answers to complex problems, to generate 800,000 reasoning examples. The Qwen2.5 32B model was then trained on those examples to reason the same way.
Unlike MoE models, where only a fraction of the parameters run per prompt, DeepSeek R1 Distill is a dense model. All 32 billion parameters are active for every prompt. This usually makes it slower than MoE models but more thorough on complex problems.
Qwen2.5-VL 32B: Vision-language model
Qwen2.5-VL 32B is built by Alibaba. It’s a multimodal model, meaning it can process both text and images.
The “VL” stands for vision language. You can upload screenshots, charts, documents, or photos and ask questions about them. The model can read text from images, explain diagrams, and extract information from tables, forms, or screenshots.
Qwen3.5 35B-A3B: Efficient multilingual model
Qwen3.5 35B-A3B is the newest model available in ExpressAI, released by Alibaba in February 2026. It uses an MoE design pattern with a total of 35 billion parameters and only 3 billion active per prompt. This keeps the model responsive to long documents and complex inputs. It supports over 200 languages and is particularly strong at coding tasks.
Nemotron 12B: Compact reasoning model
Nemotron 12B is built by NVIDIA and is the smallest model in ExpressAI, with 12 billion parameters. It uses a hybrid Mamba-Transformer architecture. Mamba layers handle most of the processing, while transformer layers are added to help the model keep track of information across long inputs. NVIDIA trained it from scratch on reasoning-focused data, including generated examples for math, science, and code.
How to choose the right model
As a general starting point, we recommend you choose a model based on what you want to use it for:
- General writing, summaries, or everyday questions? Use GPT OSS 120B. It's the most versatile model and a strong default for most tasks.
- Step-by-step reasoning, math, or data analysis? Use DeepSeek R1 Distill 32B. It works through problems methodically before producing a final answer.
- Prompt includes an image, chart, or screenshot? Use Qwen2.5-VL 32B. It's the only model that can interpret visual input.
- Code, long documents, or non-English text? Use Qwen3.5 35B-A3B. It supports over 200 languages and stays responsive to large inputs.
- Technical prompts such as formulas or debugging? Use Nemotron 12B. It's the smallest model, optimized for precision in math, science, and code.
How ExpressAI keeps your conversations private across all models
The models themselves are available on other platforms. What’s different is the privacy protections around how ExpressAI runs them.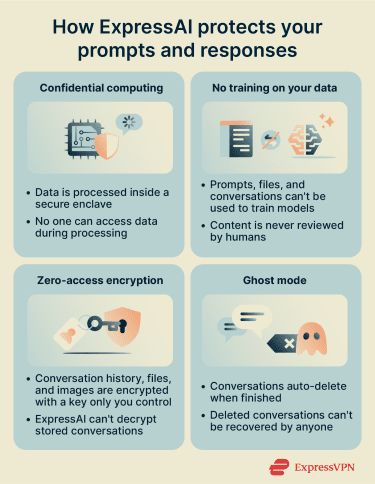
Confidential computing
ExpressAI uses confidential computing across all models. When you send a prompt, it's processed inside a secure enclave, which is an isolated environment within the server hardware. This means your data is protected not just when it’s stored or sent, but also while it’s actively being used.
The encryption keys are generated inside the enclave and never leave it. This creates cryptographic isolation: the data inside the enclave is sealed off from everything outside it. No one can access your prompts or responses, including the cloud providers hosting the servers, the model providers, and even ExpressAI.
No training on your data
Your prompts, files, and conversations can't be used to train or improve AI models. They can't be reviewed by humans either. The cryptographic isolation that protects your data during processing also prevents any of it from being extracted for other purposes.
Encrypted storage
If you choose to keep conversation history, it's protected with zero-access encryption. This means the data is encrypted with a key that only you control. ExpressAI doesn't hold a copy of that key and has no way to decrypt your stored conversations.
Ghost mode
Ghost mode sets conversations to auto-delete when you're done. Once deleted, they can't be recovered by anyone, including ExpressAI.
Independent audit
ExpressAI’s privacy architecture has been independently audited by Cure53, a trusted cybersecurity firm specializing in privacy-focused tools. The audit verified how ExpressAI protects your data, manages encryption keys, and keeps conversations isolated during both processing and storage.
This independent review confirms that the platform’s privacy measures work as promised. Any issues found were fixed before launch, so you can trust that your conversations remain private and secure by design.
FAQ: Common questions about ExpressAI models
Which ExpressAI model is best?
Can I use more than one model in the same conversation in ExpressAI?
Are my prompts private when using ExpressAI?
Does ExpressAI use my conversations to train AI models?
Will the models in ExpressAI change over time?
Take the first step to protect yourself online. Try ExpressVPN risk-free.
Get ExpressVPN