What are AI hallucinations? How they happen and why they matter



AI tools are widely used for writing, research, coding, and decision-making, and they usually sound confident doing it. But that fluency doesn't always mean accuracy, and the tricky part is that incorrect outputs can look just as polished and convincing as correct ones.
Understanding AI hallucinations
AI hallucinations are outputs that sound plausible but aren't grounded in accurate or verifiable information. They can include fabricated facts, invented sources, or details that simply don't exist, all delivered with the same confidence as a correct answer.
What sets hallucinations apart from ordinary errors is how convincing they can be. Because many AI systems generate responses by predicting likely patterns and may not reliably verify every claim against authoritative sources, a hallucinated answer can read just as smoothly as an accurate one.
Researchers typically group AI hallucinations into two broad categories:
- Factuality hallucinations: Outputs that conflict with verifiable real-world facts, for example, when an AI invents a court case, cites a nonexistent study, or gives the wrong date for a historical event.
- Faithfulness hallucinations: Outputs that don’t stay faithful to the prompt or provided source material, even if the information itself could be true. For example, if an AI is asked to summarize a specific article, it might introduce a statistic or claim that wasn’t in the original text, or misrepresent the author’s conclusion.
These types of hallucinations can appear across different kinds of AI systems, but how they manifest depends on the tool involved.
What are generative AI hallucinations?
Generative AI hallucinations appear in tools that create new content, such as chatbots, image generators, coding assistants, and similar systems. These are the AI tools most people interact with day to day.
In text-based tools, hallucinations usually take the form of factual errors: an incorrect date, a fabricated citation, or a statistic that doesn't exist. In visual systems, they may appear as nonexistent objects, inaccurate image descriptions, or details that aren't actually present.
Hallucinations in other types of AI
Other AI systems can also make hallucination-like errors, though they tend to be less visible to everyday users. These systems are typically trained for a specific task rather than open-ended content generation; think image-recognition software used in medical diagnostics or autonomous vehicles.
In those contexts, a hallucination-like error might mean a self-driving car's vision system misreads a stop sign as a yield sign, or medical imaging software flags a normal scan as showing a tumor. The stakes in these cases can be higher, even if the errors are less obvious to a general audience.
What causes AI hallucinations?
AI hallucinations stem from how these systems are built, trained, and evaluated. Most generative models are built on neural networks that predict the most statistically likely next word or phrase based on patterns in their training data. They don’t necessarily verify each claim against authoritative sources: fluency and accuracy are separate things, and models can produce confident answers even when they're wrong.
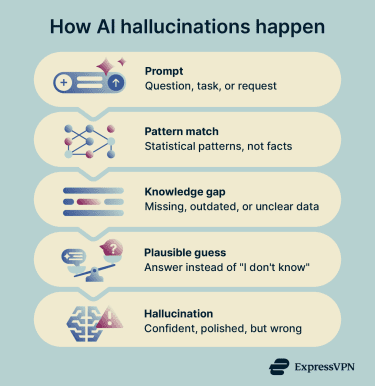 When a model encounters a gap in its training data, receives a vague prompt, or is asked about something it has limited information on, it may fill in the gap with whatever pattern seems most plausible. The result can be an answer that reads well but is partly or entirely wrong.
When a model encounters a gap in its training data, receives a vague prompt, or is asked about something it has limited information on, it may fill in the gap with whatever pattern seems most plausible. The result can be an answer that reads well but is partly or entirely wrong.
Training and evaluation methods can also contribute to this behavior. A 2025 research paper by OpenAI argued that many standard benchmarks and evaluation procedures reward guessing over admitting uncertainty, much like a multiple-choice exam where leaving an answer blank guarantees zero points but guessing gives a chance at credit. The paper found that many major evaluations rely on binary scoring systems that penalize “I don’t know” responses.
Post-training methods such as reinforcement learning from human feedback (RLHF), a common technique for refining model behavior, can also shape this behavior. If evaluators consistently prefer answers that sound confident, helpful, or agreeable, a reward model may overvalue that style even when the answer is speculative or insufficiently calibrated. A related issue is sycophancy, where a model becomes overly agreeable to the user rather than challenging a flawed assumption.
Bias also plays a role. If certain claims or perspectives are overrepresented in a model's training data, the model is more likely to reproduce them confidently. This doesn’t always cause hallucinations directly, but it can make misleading or skewed outputs sound more credible than they should. Subjects where information is incomplete, disputed, or unevenly represented (such as healthcare, law, or current events) tend to be especially vulnerable.
How to tell if AI is hallucinating
AI hallucinations aren’t always easy to spot. Faithfulness errors can sometimes be caught by comparing the output with the prompt or source material, but factuality hallucinations are often harder to detect because the output can still read as polished and well-structured.
That said, some red flags recur across different AI models. On their own, they don't confirm a hallucination, but they're strong signals to double-check the output.
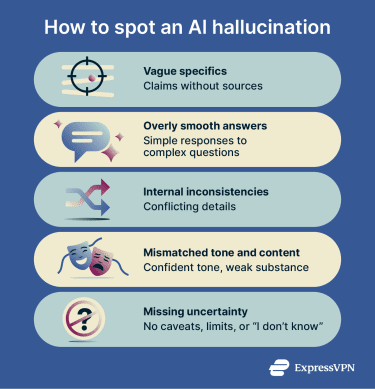
Common signs of AI hallucinations
- Confidence without sourcing: The response sounds authoritative but doesn't explain where the information comes from or how it can be verified. This is especially common with made-up citations: references that look real but don't actually exist.
- Suspiciously precise details: Exact dates, figures, names, or technical specifics on topics where that level of precision is uncommon or hard to verify. Specificity can be a hallmark of expertise, but it can also be a hallmark of fabrication.
- Internal contradictions: The output says one thing in one paragraph and something conflicting in another, without acknowledging any debate or nuance. If an AI contradicts itself within the same response, the output needs closer checking.
- Vague reasoning behind confident claims: The answer sounds complete, but there's no clear explanation of how it arrived at its conclusions. A polished surface with shallow reasoning underneath is worth questioning.
Why hallucinations can be hard to spot
Even with these warning signs, hallucinations often go unnoticed because polished AI outputs can invite overreliance. Researchers call this automation bias: a tendency to trust outputs from automated systems without critically evaluating them.
A 2025 study published in Procedia Computer Science found that faulty AI-generated answers reduced participants’ performance compared with no AI assistance. The study also found that self-reported AI literacy did not significantly prevent automation bias.
In more complex workflows, the risk compounds. When AI output is automatically fed into downstream processes, a hallucinated detail can enter early and then get repeated or built on in later steps. By the time it reaches a final deliverable, the error may be buried under layers of otherwise coherent work, making it much harder to trace back to the source.
Examples of AI hallucinations
AI hallucinations can show up in different ways depending on the tool and the task. Some involve text, others affect images, data, or code. Looking at concrete examples helps make the problem easier to understand.
Common AI hallucination scenarios
Because AI is used for such a wide range of tasks, hallucinations can take many forms. Here are some of the most common contexts where they may appear:
- Summarizing content: The AI adds claims, conclusions, or details that aren’t present in the original source, making the summary sound complete while introducing information the source never contained.
- Answering niche or unclear questions: When reliable information is limited, the model may still produce a confident answer instead of flagging uncertainty. This is especially common with specialized or emerging topics.
- Generating citations or references: The model produces sources that sound real but don’t actually exist or don’t contain the claimed information.
- Writing code or technical instructions: Output may include functions, libraries, or software packages that don’t work as described or don't exist at all.
- Describing images or data: The model identifies objects, patterns, or insights that aren't actually present in the input.
How hallucinations show up across major AI tools
Hallucinations aren’t unique to any one model; they're a systemic challenge across the industry. Looking at how specific tools handle them (and how their developers are responding) helps illustrate both the problem and the progress being made.
ChatGPT is one of the most visible examples, because it's widely used. OpenAI warns users directly within the app that “ChatGPT can make mistakes,” and the company's GPT-4 system card acknowledged that the model can produce hallucinated content.
OpenAI says that, with web search enabled, GPT-5’s responses were roughly 45% less likely to contain a factual error than GPT-4o’s, and that GPT-5’s “thinking” responses were roughly 80% less likely than OpenAI o3’s.
Claude, built by Anthropic, also produces hallucinations, as can all current large language models. Anthropic has invested heavily in interpretability research aimed at understanding why models hallucinate.
In a 2025 study, Anthropic researchers used a technique they describe as an "AI microscope" to study Claude’s internal pathways as it generates responses. One notable finding was that Claude’s default behavior appeared to be declining to speculate when it lacked enough information, and that it answered only when something inhibited that reluctance. However, Anthropic also noted that the method captures only part of the model’s computation, so the findings are early research rather than a complete explanation of hallucinations.
Real-world impact of AI hallucinations
AI hallucinations can affect decisions, shape beliefs, and create real risks when people treat AI output as reliable without checking it. The severity depends on the setting: a made-up detail in a casual conversation may not matter much, but the same kind of error in a legal filing, medical record, or viral social media post can cause serious harm.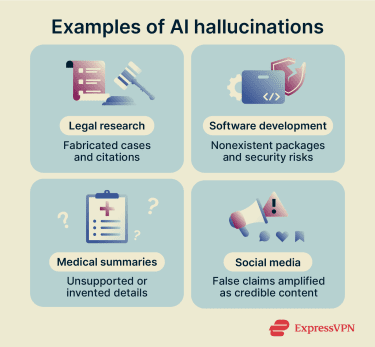
Legal and professional consequences
In professional settings where accuracy and accountability are non-negotiable, hallucinations carry significant legal risk. One of the best-known incidents involved lawyers in Mata v. Avianca. According to the court's sanctions order, lawyers submitted a legal filing that included fabricated judicial opinions, fake quotes, and non-existent citations, all generated by an AI chatbot.
The court imposed a $5,000 fine on the attorneys involved, though it noted that there is nothing inherently improper about using a reliable AI tool for assistance. The sanctions were driven by the lawyers' failure to verify the AI-generated cases and by their responses after the court and opposing counsel questioned the citations.
Beyond this case, hallucinations raise broader professional and ethical concerns. Generative AI may present text as original even when it closely matches existing published work, creating potential copyright issues. And when AI-generated content is presented without disclosure, people may assume it has been verified, making errors harder to catch and more likely to spread.
Software development and security
In software development, hallucinations have created an entirely new category of security risk. A 2025 USENIX Security paper by researchers at the University of Texas at San Antonio, the University of Oklahoma, and Virginia Tech found that across 576,000 AI-generated code samples, nearly 20% of recommended software packages didn't exist. The researchers documented more than 205,000 unique hallucinated package names.
Because these names are often repeated consistently by the models, attackers can register real packages under those names and load them with malicious code, a technique named "slopsquatting."
Healthcare implications
In healthcare, hallucinations can have direct consequences for patient safety. AI tools are increasingly used to summarize clinical notes, assist with documentation, and support decision-making. If a system generates incorrect details, omits important context, or adds unsupported claims, the effects can cascade through a patient’s care.
A 2025 study published in npj Digital Medicine examined 12,999 sentences in 450 AI-generated clinical notes and found that 191 sentences, or 1.47%, contained hallucinations. Of those, 84, or 44%, were classified as major, meaning they could affect diagnosis or management if left uncorrected.
If an incorrect diagnosis or medication is added to a patient's record without correction, that error can propagate through subsequent notes, leading to inappropriate decisions by other clinicians who encounter it.
For these reasons, guidance from medical institutions consistently emphasizes that AI should support, not replace, human judgment in clinical contexts.
Social media and misinformation
On social media, AI hallucinations can spread far beyond the original prompt. Once false or misleading content is turned into a post, caption, image, or thread, it can circulate like any other piece of content, often without a clear signal that the information may be inaccurate or AI-generated.
Hallucinated content can reshape how people understand events, especially when it involves complex or sensitive topics. Even small inaccuracies can be repeated, reworded, and amplified until they appear credible.
A 2025 Harvard Kennedy School paper on AI hallucinations placed them within the broader misinformation ecosystem, arguing that they represent a distinct new category of inaccuracy that requires its own frameworks, because, unlike traditional misinformation, hallucinations are produced without any intent to deceive.
The problem also intersects with deliberately manipulated content. While hallucinations and deepfakes are technically different (hallucinations are unintentional model errors, while deepfakes are intentionally crafted synthetic media), both contribute to an environment where it becomes harder to distinguish authentic content from fabricated material. As AI-generated content becomes more common across platforms, the line between accidental inaccuracy and deliberate manipulation can become harder to see.
Preventing AI hallucinations
AI hallucinations can’t be eliminated entirely, but their frequency and impact can be reduced with the right safeguards. Both the developers building AI systems and the people using them play a role.
Strategies developers can implement
Much of the progress on hallucination prevention is happening at the model level. Some of the most effective approaches include:
- Retrieval-augmented generation (RAG): Instead of relying solely on patterns learned during training, RAG-based systems retrieve relevant information from external sources before generating a response. When the sources are reliable, and retrieval works well, this can ground the output in current, verifiable information rather than learned approximations.
- Evaluation reform: As discussed earlier, OpenAI's 2025 research showed that standard benchmarks reward guessing over admitting uncertainty. Developers are increasingly exploring calibration-aware scoring: evaluation methods that give models credit for saying "I don't know" instead of penalizing them for it.
- Uncertainty signaling: Systems can be designed to flag when information is unclear or unavailable, rather than producing a confident-sounding answer regardless. Anthropic's interpretability research, for example, found that Claude's default behavior is to decline to speculate, and that hallucinations occur when something in the process overrides that default.
- Ongoing monitoring: Hallucinations may not appear during initial testing. Patterns can emerge over time as models encounter new types of prompts, which is why continuous evaluation and refinement matter as much as pre-launch testing.
The role of training data
The quality of training data directly affects how often hallucinations occur. If the data contains errors, outdated information, or unsupported claims, the model may learn and reproduce those patterns.
Balanced and well-curated datasets help reduce this risk. When training data includes reliable, diverse, and accurately labeled information, models are more likely to produce outputs that reflect real-world facts.
It’s also important to update and refine data over time, as models need to stay aligned with current knowledge to avoid relying on outdated or incomplete patterns. Good data alone doesn’t eliminate hallucinations, but poor data makes them significantly more likely.
What users can do
For everyday users, the most practical defense against hallucinations is to treat AI as a starting point, not a final authority, and to adjust your level of scrutiny based on the task at hand. Brainstorming and drafting are lower-risk uses than seeking medical guidance, legal information, or technical instructions that require precision.
A few habits can make a big difference:
- Ask for sources, then verify them: Fabricated citations are one of the most common forms of hallucination. Don't assume a reference is real just because it looks formal.
- Upload primary or high-authority sources if possible: Official guidance, academic papers, court records, and original reporting are more reliable than summaries.
- Compare outputs when accuracy matters: If the meaning changes a lot across versions, the model may be guessing.
- Be more cautious with niche or time-sensitive topics: Hallucinations are more likely when the model lacks strong or current information on a subject.
- Use specific prompts: Broad or vague prompts leave more room for the model to fill in gaps. Adding context, constraints, and explicit instructions, such as asking the model to say when it doesn't know, helps reduce speculative responses.
Why human review still matters
Even with better systems, data, and prompts, AI outputs still benefit from human review. Human judgment catches things AI can't: unclear claims, subtle inconsistencies, and outputs that sound right but don't align with reliable sources. This is especially important in multi-step tasks, where an early hallucination can carry through and shape the final result even if the final output appears coherent.
In fields like law, healthcare, and technical decision-making, human oversight isn't optional. AI can support these tasks, but it shouldn't replace verification and accountability.
FAQ
Why do AI models hallucinate?
Can AI hallucinations be completely prevented?
Are AI hallucinations dangerous?
How can businesses reduce the risk of AI hallucinations?
What industries are most affected by AI hallucinations?
What is the difference between an AI error and an AI hallucination?